I wanted to know if anyone ever had known cases of HDDs fail because of that drive? I’m using the HL15 for 2 months know and today during my TrueNAS ZFS Scrub I had 2 HDDs fail at once. I don’t want to “accuse” 45HomeLab for this, it could totally be a case of a defect HDD batch - I just wanted to get some field reports from y’all if somebody also had experience this, maybe due to the dense placing of the drives and/or the vibration of the HL15.
Either way, I’ve already opened an RMA at WD for the wrong HDDs.
That sucks you had two drives fail. Sorry you’re having to deal with that. I’m assuming your pool was able to tolerate that failure?
I’m coming up on a year with my HL15 and I haven’t had any drive failures with a pretty full system. I have two ZFS pools: 1) Z2 with 8x Seagate Exos drives plus a Mirror LOG with 2x Enterprise SATA SSD’s and 2) a ZFS Mirror with 4x Crucial SSD’s. That puts me at 14 out of 15 slots with a drive in it. All my spinning disks are clustered together in the first 8 slots. I also have a 4x NVME carrier card in a lot for Special VDEV’s and an Arc GPU for transcoding.
My experience is actually the opposite. The enterprise servers from Supermicro, HP, Dell, etc. with caddies have less airflow. Eliminating the caddies allows for easy airflow around the drives.
Keep an eye on drive temps. Go to the netdata reports and look back at the historical info for the drives that failed. Also be sure the case fans are providing enough airflow if you have them hooked up for adjustable RPM. Some people are tuning the RPM way down for low noise, but not allowing enough airflow.
Also you can check out Backblaze’s reports of drive failure rates for each drive model they have or had in service, some drives fail a lot more than others. I have mostly Seagate drives, but have had a few of those fail over the years, but some of those were transplanted from a Supermicro where they got quite hot, so I don’t blame the HL15.
Was it just ZFS errors that you noticed? Did any of the SMART data also indicate the drives were bad?
I ask because when I first received my HL15, my unit marginal/bad cables which caused ZFS errors in my pool but the drives themselves were actually fine. It was really easy initially to point to the drives and took a lot of troubleshooting for me to figure out that wasn’t the case. From that perspective, I can appreciate you checking here on other possibilities.
Pool File-Server state is DEGRADED: One or more devices are faulted in
response to persistent errors. Sufficient replicas exist for the pool to
continue functioning in a degraded state.
The following devices are not healthy:
Disk ATA WDC WD201KRYZ-01 SERIALNUMBER#1 is FAULTED
The Second drive got me this messages:
Pool File-Server state is DEGRADED: One or more devices are faulted in
response to persistent errors. Sufficient replicas exist for the pool to
continue functioning in a degraded state.
The following devices are not healthy:
Disk ATA WDC WD201KRYZ-01 SERIALNUMBER#1 is FAULTED
Disk ATA WDC WD201KRYZ-01 SERIALNUMBER#2 is FAULTED
Device: /dev/da3 [SAT], not capable of SMART self-check.
Device: /dev/da3 [SAT], failed to read SMART Attribute Data.
Sorry, I was just responding to your comment about the HL15 having “dense placing of the drives” and saying they really aren’t that densely packed IMO compared to other rack mountable storage servers. At 32C the temps are fine.
I was also going to mention what Ryan mentioned. Although 2 drives could just be coincidence; if this happened during a scrub (ie, under sustained load), and at 2 months you probably haven’r done a lot of scrubs, you might want to verify there isn’t something hardware related (HBA, cables, …) corrupting the data.
I guess you’ve already sent the drives for RMA?, but seeing a full smartctrl or crystal disk info report for the failed drives might help quantify the error; TrueNAS can be pretty aggressive about sending up flags at the first sign of trouble (not a bad thing).
I thought one particular cables issue that got lengthy discussion here was more around SAS drives operating at 12gbps speeds, but I could be mixing threads.
It’s certainly possible. There should be more clues in either smartctl -x or in dmesg if that’s the case. When I had the bad cables, I saw these errors like these in or around the time of the ZPOOL reporting problems:
[Thu Dec 21 20:10:57 2023] sd 10:0:7:0: [sdc] tag#658 FAILED Result: hostbyte=DID_SOFT_ERROR driverbyte=DRIVER_OK cmd_age=0s
[Thu Dec 21 20:10:57 2023] sd 10:0:7:0: [sdc] tag#658 CDB: Write(16) 8a 00 00 00 00 00 07 0f bc 68 00 00 08 08 00 00
[Thu Dec 21 20:10:57 2023] I/O error, dev sdc, sector 118471784 op 0x1:(WRITE) flags 0x700 phys_seg 35 prio class 2
[Thu Dec 21 20:10:57 2023] zio pool=SEAGATE4ODDZ2 vdev=/dev/disk/by-vdev/1-11-part1 error=5 type=2 offset=60656504832 size=1052672 flags=40080c80
If you still have the drives and willing to play around, I’d drop down to the command prompt and try a few things. You can use zpool clear to reset the ZFS errors and run the scrub again. You could also kick off a long smart test (command line or TrueNAS UI) on those drives to see if you get anymore information.
@DigitalGarden you’re remembering correctly. That was my issue where the cables worked at 6gbps and not at the auto negotiated 12gpbs. 45HomeLab sent me a new set and it’s been working just fine ever since. The original set must have just been manufactured slightly out of tolerance.
Oh okay, that’s good to know. This has been my first Server Chassis so I didn’t know how dense other cases are.
I first startet the HL15 in the last week of October and have had a scrub run every week since then. There hasn’t been any error so far - until today.
I have the drive still here, since I was at work when I got the message, that my TrueNAS system has been degraded. I will check the drive tomorrow on my PC for further S.M.A.R.T. errors.
Since I only have SATA drives, could this cable-thing also occur to my problem?
Any chance you can provide a more complete output from the smartctl info on the bad drive? Each drive manufacture has a slightly different implementation of SMART but you should get more than just that snippet. I include an example of a SATA SSD from my own HL15 running TrueNAS Scale.
One initial thought observation: I don’t have any hits on Phy Event Counter 0x0009 on my drive. Could be something but could also be totally normally. This is how I started suspecting a bad cable in my system. I slowly started seeing interface resets and errors logged in SMART spread across my drives as I did my testing.
Truenas-HL15# smartctl -x /dev/sdo
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.6.44-production+truenas] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Crucial/Micron Client SSDs
Device Model: CT4000MX500SSD1
Serial Number: 2331E*******
LU WWN Device Id: 5 00a075 1e8657431
Firmware Version: M3CR046
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: Solid State Device
Form Factor: 2.5 inches
TRIM Command: Available
Device is: In smartctl database 7.3/5625
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Mon Dec 9 17:22:07 2024 CST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
AAM feature is: Unavailable
APM feature is: Disabled
Rd look-ahead is: Enabled
Write cache is: Enabled
DSN feature is: Unavailable
ATA Security is: Disabled, NOT FROZEN [SEC1]
Wt Cache Reorder: Unknown
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 0) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 30) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x0031) SCT Status supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 100 100 000 - 0
5 Reallocate_NAND_Blk_Cnt -O--CK 100 100 010 - 0
9 Power_On_Hours -O--CK 100 100 000 - 7791
12 Power_Cycle_Count -O--CK 100 100 000 - 20
171 Program_Fail_Count -O--CK 100 100 000 - 0
172 Erase_Fail_Count -O--CK 100 100 000 - 0
173 Ave_Block-Erase_Count -O--CK 099 099 000 - 23
174 Unexpect_Power_Loss_Ct -O--CK 100 100 000 - 7
180 Unused_Reserve_NAND_Blk PO--CK 000 000 000 - 231
183 SATA_Interfac_Downshift -O--CK 100 100 000 - 0
184 Error_Correction_Count -O--CK 100 100 000 - 0
187 Reported_Uncorrect -O--CK 100 100 000 - 0
194 Temperature_Celsius -O---K 080 062 000 - 20 (Min/Max 0/38)
196 Reallocated_Event_Count -O--CK 100 100 000 - 0
197 Current_Pending_ECC_Cnt -O--CK 100 100 000 - 0
198 Offline_Uncorrectable ----CK 100 100 000 - 0
199 UDMA_CRC_Error_Count -O--CK 100 100 000 - 0
202 Percent_Lifetime_Remain ----CK 099 099 001 - 1
206 Write_Error_Rate -OSR-- 100 100 000 - 0
210 Success_RAIN_Recov_Cnt -O--CK 100 100 000 - 0
246 Total_LBAs_Written -O--CK 100 100 000 - 32014375368
247 Host_Program_Page_Count -O--CK 100 100 000 - 448716948
248 FTL_Program_Page_Count -O--CK 100 100 000 - 361580314
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
General Purpose Log Directory Version 1
SMART Log Directory Version 1 [multi-sector log support]
Address Access R/W Size Description
0x00 GPL,SL R/O 1 Log Directory
0x01 SL R/O 1 Summary SMART error log
0x02 SL R/O 1 Comprehensive SMART error log
0x03 GPL R/O 1 Ext. Comprehensive SMART error log
0x04 GPL,SL R/O 8 Device Statistics log
0x06 SL R/O 1 SMART self-test log
0x07 GPL R/O 1 Extended self-test log
0x09 SL R/W 1 Selective self-test log
0x10 GPL R/O 1 NCQ Command Error log
0x11 GPL R/O 1 SATA Phy Event Counters log
0x24 GPL R/O 88 Current Device Internal Status Data log
0x25 GPL R/O 128 Saved Device Internal Status Data log
0x30 GPL,SL R/O 9 IDENTIFY DEVICE data log
0x80-0x9f GPL,SL R/W 16 Host vendor specific log
0xe0 GPL,SL R/W 1 SCT Command/Status
0xe1 GPL,SL R/W 1 SCT Data Transfer
SMART Extended Comprehensive Error Log Version: 1 (1 sectors)
No Errors Logged
SMART Extended Self-test Log Version: 1 (1 sectors)
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 7749 -
# 2 Short offline Completed without error 00% 7578 -
# 3 Short offline Completed without error 00% 7407 -
# 4 Short offline Completed without error 00% 7237 -
# 5 Short offline Completed without error 00% 7066 -
# 6 Short offline Completed without error 00% 6895 -
# 7 Extended offline Completed without error 00% 6847 -
# 8 Short offline Completed without error 00% 6725 -
# 9 Short offline Completed without error 00% 6555 -
#10 Short offline Completed without error 00% 6387 -
#11 Short offline Completed without error 00% 6220 -
#12 Extended offline Completed without error 00% 6100 -
#13 Short offline Completed without error 00% 6052 -
#14 Short offline Completed without error 00% 5885 -
#15 Short offline Completed without error 00% 5718 -
#16 Short offline Completed without error 00% 5549 -
#17 Short offline Completed without error 00% 5413 -
#18 Short offline Completed without error 00% 5246 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
SCT Status Version: 3
SCT Version (vendor specific): 1 (0x0001)
Device State: Active (0)
Current Temperature: 20 Celsius
Power Cycle Min/Max Temperature: 14/26 Celsius
Lifetime Min/Max Temperature: 0/38 Celsius
Under/Over Temperature Limit Count: 0/0
SCT Temperature History Version: 2
Temperature Sampling Period: 1 minute
Temperature Logging Interval: 1 minute
Min/Max recommended Temperature: 0/100 Celsius
Min/Max Temperature Limit: 0/100 Celsius
Temperature History Size (Index): 128 (57)
Index Estimated Time Temperature Celsius
58 2024-12-09 15:15 19 -
... ..( 60 skipped). .. -
119 2024-12-09 16:16 19 -
120 2024-12-09 16:17 20 *
121 2024-12-09 16:18 19 -
... ..( 6 skipped). .. -
0 2024-12-09 16:25 19 -
1 2024-12-09 16:26 20 *
2 2024-12-09 16:27 19 -
... ..( 36 skipped). .. -
39 2024-12-09 17:04 19 -
40 2024-12-09 17:05 20 *
41 2024-12-09 17:06 19 -
42 2024-12-09 17:07 20 *
43 2024-12-09 17:08 19 -
44 2024-12-09 17:09 20 *
45 2024-12-09 17:10 19 -
46 2024-12-09 17:11 19 -
47 2024-12-09 17:12 20 *
... ..( 5 skipped). .. *
53 2024-12-09 17:18 20 *
54 2024-12-09 17:19 19 -
55 2024-12-09 17:20 20 *
56 2024-12-09 17:21 19 -
57 2024-12-09 17:22 20 *
SCT Error Recovery Control command not supported
Device Statistics (GP Log 0x04)
Page Offset Size Value Flags Description
0x01 ===== = = === == General Statistics (rev 1) ==
0x01 0x008 4 20 --- Lifetime Power-On Resets
0x01 0x010 4 7791 --- Power-on Hours
0x01 0x018 6 32014375368 --- Logical Sectors Written
0x01 0x020 6 388956639 --- Number of Write Commands
0x01 0x028 6 36707367537 --- Logical Sectors Read
0x01 0x030 6 184823470 --- Number of Read Commands
0x01 0x038 6 2279265625 --- Date and Time TimeStamp
0x04 ===== = = === == General Errors Statistics (rev 1) ==
0x04 0x008 4 0 --- Number of Reported Uncorrectable Errors
0x04 0x010 4 7 --- Resets Between Cmd Acceptance and Completion
0x05 ===== = = === == Temperature Statistics (rev 1) ==
0x05 0x008 1 20 --- Current Temperature
0x05 0x010 1 19 --- Average Short Term Temperature
0x05 0x018 1 19 --- Average Long Term Temperature
0x05 0x020 1 38 --- Highest Temperature
0x05 0x028 1 0 --- Lowest Temperature
0x05 0x030 1 26 --- Highest Average Short Term Temperature
0x05 0x038 1 0 --- Lowest Average Short Term Temperature
0x05 0x040 1 26 --- Highest Average Long Term Temperature
0x05 0x048 1 0 --- Lowest Average Long Term Temperature
0x05 0x050 4 0 --- Time in Over-Temperature
0x05 0x058 1 70 --- Specified Maximum Operating Temperature
0x05 0x060 4 0 --- Time in Under-Temperature
0x05 0x068 1 0 --- Specified Minimum Operating Temperature
0x06 ===== = = === == Transport Statistics (rev 1) ==
0x06 0x008 4 190 --- Number of Hardware Resets
0x06 0x010 4 75 --- Number of ASR Events
0x06 0x018 4 0 --- Number of Interface CRC Errors
0x07 ===== = = === == Solid State Device Statistics (rev 1) ==
0x07 0x008 1 1 --- Percentage Used Endurance Indicator
|||_ C monitored condition met
||__ D supports DSN
|___ N normalized value
Pending Defects log (GP Log 0x0c) not supported
SATA Phy Event Counters (GP Log 0x11)
ID Size Value Description
0x0001 2 0 Command failed due to ICRC error
0x0002 2 0 R_ERR response for data FIS
0x0003 2 0 R_ERR response for device-to-host data FIS
0x0004 2 0 R_ERR response for host-to-device data FIS
0x0005 2 0 R_ERR response for non-data FIS
0x0006 2 0 R_ERR response for device-to-host non-data FIS
0x0007 2 0 R_ERR response for host-to-device non-data FIS
0x0008 2 0 Device-to-host non-data FIS retries
0x0009 2 0 Transition from drive PhyRdy to drive PhyNRdy
0x000a 2 33 Device-to-host register FISes sent due to a COMRESET
0x000b 2 0 CRC errors within host-to-device FIS
0x000d 2 0 Non-CRC errors within host-to-device FIS
0x000f 2 0 R_ERR response for host-to-device data FIS, CRC
0x0010 2 0 R_ERR response for host-to-device data FIS, non-CRC
0x0012 2 0 R_ERR response for host-to-device non-data FIS, CRC
0x0013 2 0 R_ERR response for host-to-device non-data FIS, non-CRC
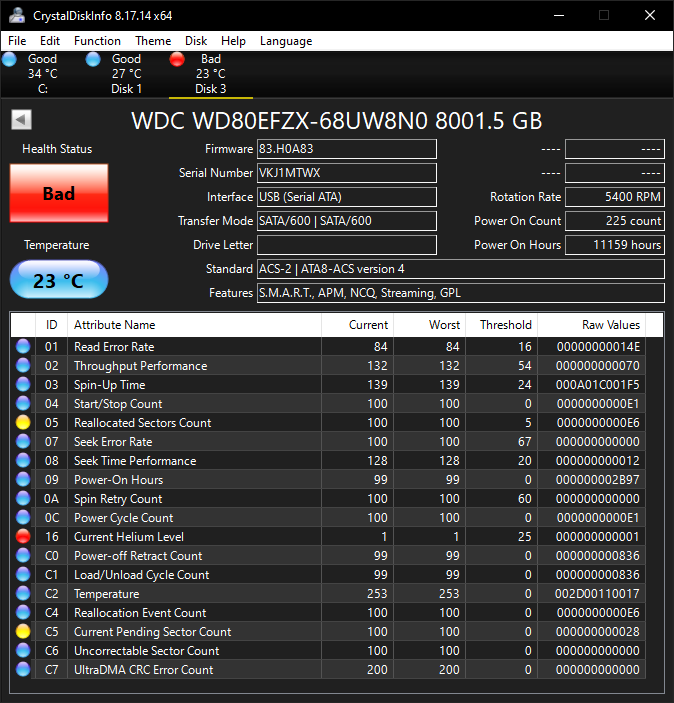
You may know all of this, if so please just ignore. Here is some example SMART output from two failed drives I have waiting to go to eWaste, one a 12 TB Seagate and the other an 8 TB WD.
In Windows you can use CrystalDiskInfo to get a good visual cue to a drive’s health. I think there are similar tools for Linux desktop like GSmartControl but have not used that. I usually use a device like this to plug the drive into my Windows laptop;
The 12 TB drive just reports as a caution in CDI for the Reallocated Sectors Count, but TrueNAS was pretty persistent with notifications wanting me to replace the drive (I don’t recall if ZFS actually had the pool DEGRADED or not).
The 8 TB drive is older and wasn’t in a TrueNAS system; it took a lot before Windows (7?) finally started reporting the drive as bad. Current Pending Sector Count and Reallocated Sectors Count are more typical of the errors I see with the drives I’ve had fail. I think the helium level thing is just because it’s been sitting for years, and not an original failure mode.
Within TrueNAS Scale you can go to System\Shell or open up an SSH terminal if you have that enabled and use the command “sudo smartctl -a /dev/sdx” to see similar output, replacing /dev/sdx with the mount point for the drive. It looks from your output you’re maybe running TrueNAS Core? So your command may be a little different for FreeBSD. If this is a new system you might consider running Scale instead, as that is the Future, but that’s a different topic.
There’s a lot in the output, but for my 12 TB drive there is a line;
SMART overall-health self-assessment test result: PASSED
With the command line output it isn’t quite as obvious which thresholds are causing warnings or errors, if it matters.
You can also schedule or manually run more extensive SMART tests from the command line or in the TrueNAS GUI from Storage\Manage Disks[select a disk] or Data Protection\Periodic SMART tests. But that’s more preemptive than post-mortem diagnostic.
I’m guessing from your additional info that the drives were actually starting to report errors, and there’s not some other hardware issue with your build, but it doesn’t hurt to confirm. 45Drives has been building variants of these pods with vertically oriented caddyless insertion for well over 10 years, and for clients with large databases and datacenters; if there were a fundamental engineering issue with the design re drive failue I think it would have been identified and highlighted by now.
Yes, I’m using TrueNAS Core (like you said, that’s a topic for itself )
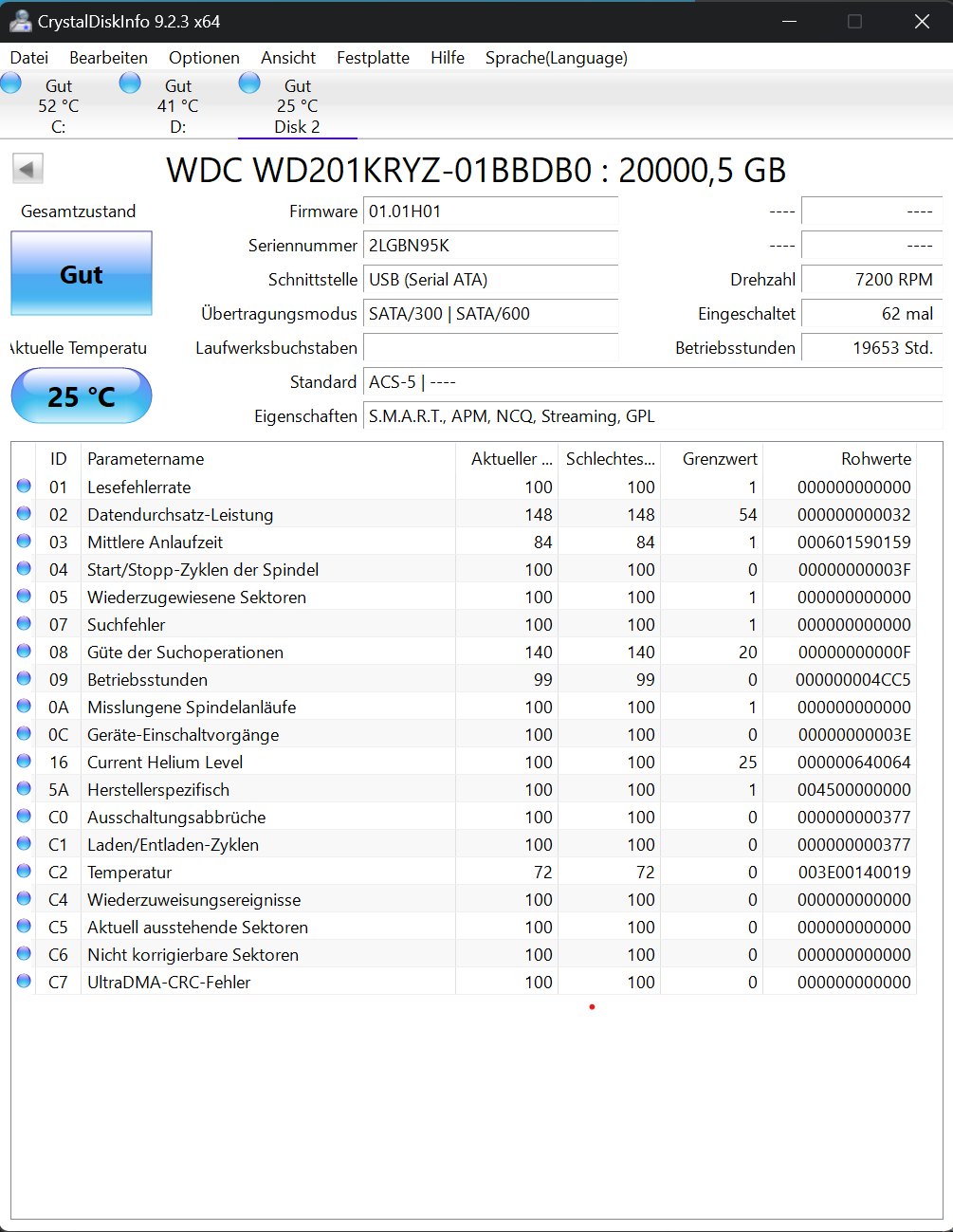
I have yet to test my drive on my PC using CrystalDiskInfo, but I will this evening when I come home from work.
The thing is, I run weekly S.M.A.R.T.-tests to get a better feeling of when a drive could fail and since I haven’t gotten any warnings before, it took me by surprise, I also posted an output of smartctl -x on my comment above.
I was kind of thinking, that the HL15 was not the reason for my drive failures but I was just making sure
I’m not seeing an issue in that SMART output. It doesn’t mean it’s not there, just I don’t see it.
For some reason I thought these were new-ish drives. Is the cumulative power on time for the other failed drive also 2 years and 3 months? Hard (but not impossible) for drives that have been running for two years to be a bad batch.
Like David mentioned, I’m also not seeing that these drives report as bad, but we do need to take that with a grain salt as SMART reports this drive is not in the database. There’s a higher chance then of smartmontools missing failures or even reporting false errors. It looks like Core is using a version that’s several point releases behind the current 7.4.
Originally, I was homing in on “Number of Hardware Resets” under Device Statistics (GP Log 0x04) seemed very high for a two month old drive. Then I also noticed that the power on hours was over two years. Maybe these were refurbed or recertified drives or came from another system?
Anyway, here are a few suggestions on what to try next if you’re willing:
Check the SMART data on a newer version that (hopefully) has the drive in the data base. When I used TrueNAS Core, I figured out a way just to update smartmontools at every boot to avoid a bug in the software until IXsystems fixed it. Not a recommended approach by any means but doable. You could also boot into a newer live distro of Linux or move the drives in another system also running newer Linux or Windows plus Crystal DiskMark. I have to imagine that WD might even have some software on their website for checking drives. I know Seagate does.
Rerun an Offline Extended test. I see the last one for this drive was interrupted at 90% due to host reset. It probably would have come back ok but I’d do that just to be sure. Again, preferably on a newer version of smartmontools or another software.
Because of the age of the drive, I think there has been a miscommunication on my part - The HL15 was first set up 2 months ago but the drives (and my whole system) is older. I moved from a normal PC case to the HL15 in October but TrueNAS itself has been running since 2022.
I plugged the HDD into my PC and checked it via CrystalDiskInfo and it says the drive is in good condition: