so here is a worrying thing that has now occurred on my new HL15 fully burned in.
i had 1x WD Gold 18TB drives (WD181KRYZ) in slots 1-6 through 1-15 and have been running with these drives for days now without issue.
I proceeded to install two new drives (WD white label WD120EDAZ) in slots 1-1 and 1-2 and when i installed the drive in slot 2, the system cut power about 5 seconds later. it was not a shutdown, the system just cut power.
i removed the drives from slots 1-1 and 1-2 and then tried a 8TB WD Purple drive (WD82PURZ) in slot 2 and it seemed to work fine.
i left the system running overnight and when i cam into my office this morning the system was powered OFF!
I have moved the drives from slots 1-6 though 1-15 to slots 1-1 through 1-10 for troubleshooting to see if the system shuts down at all with different drives in those slots. so far for the last 30 mins everything is working fine, drives are recognized and i am writing data to them fine.
what could be causing this? the drive that i first put into slot 1-2 that caused the near immediate power off works fine in a SATA to USB adapter to verify it is functional. could i have a bad backplane?
Anything else connected internally, like SSDs or PCIE cards? The system has the 1000W Corsair PSU? An immediate power off would be one thing for a short, but a delay of 5 seconds seems strange. If you could track down any messages to what the system was doing last night when it shut off that might help, was it under load?
Some other possibilities might be a bad cable associated with slot 2, or bad thermal paste on the mobo. Info@45homelab.com can help identify a bad backplane, I don’t know the process.
yes i have a Nvidia RTX A400 in the PCIe 16x slot
i have a intel 310 4x port 1GB Ethernet network card
and finally i have a SLI-9400-8E in one slot
those have been installed since day 1 without issues over the course of 5x days. it was only when i tried using slot 2 last night that things seem to have gone weird.
the system was under near no load, i have been copying data off my old systems onto the new system, but again that has been going fine for a couple of days without issue.
so far so good. i will reply back later tonight if NOTHING happens over the reminder of the day or i will reply when the system shuts down again.
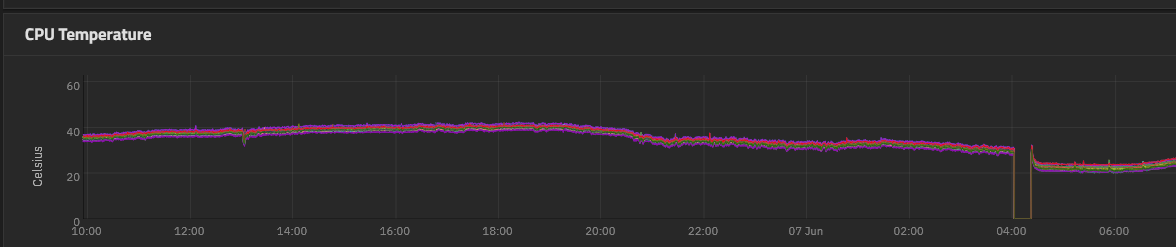
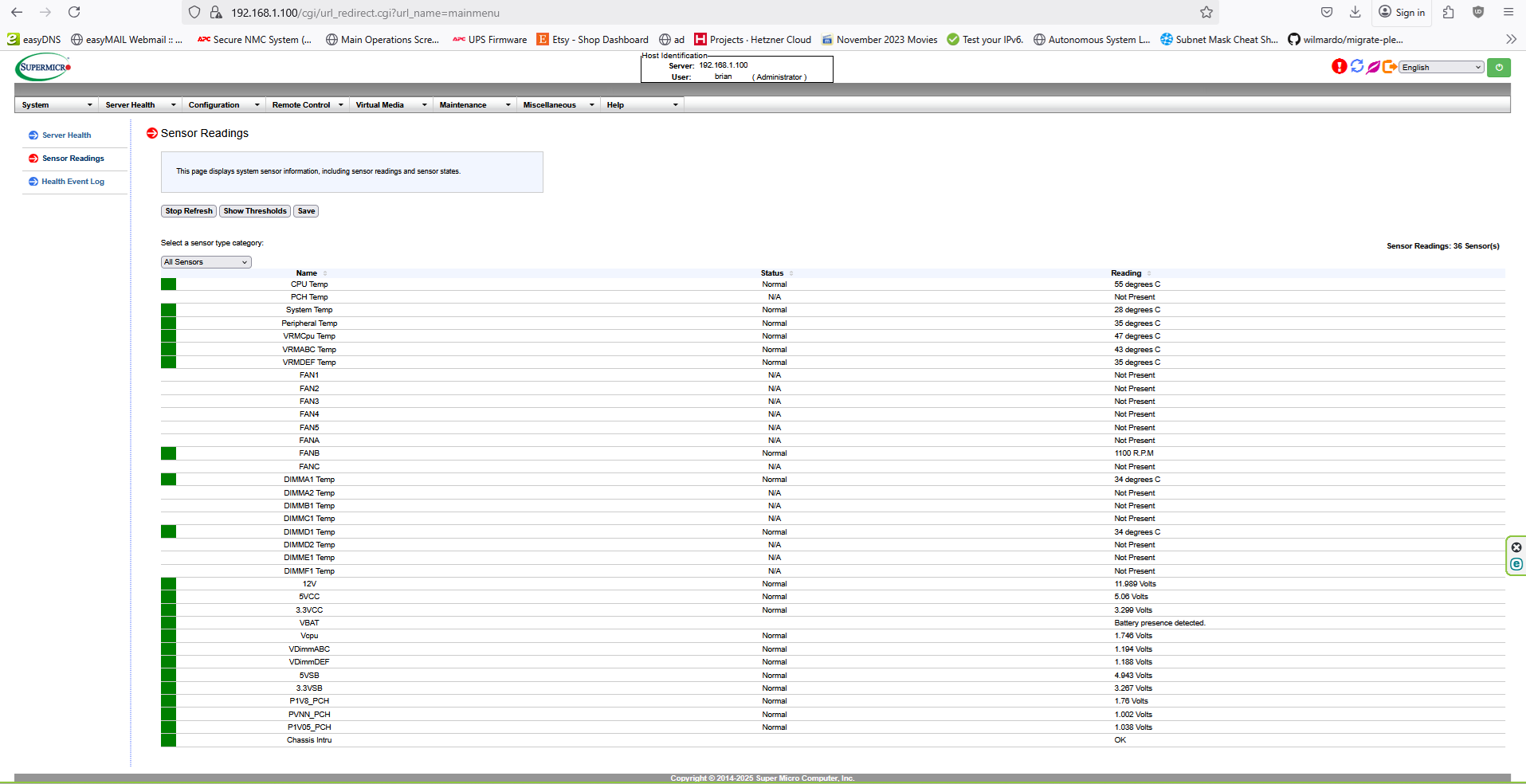
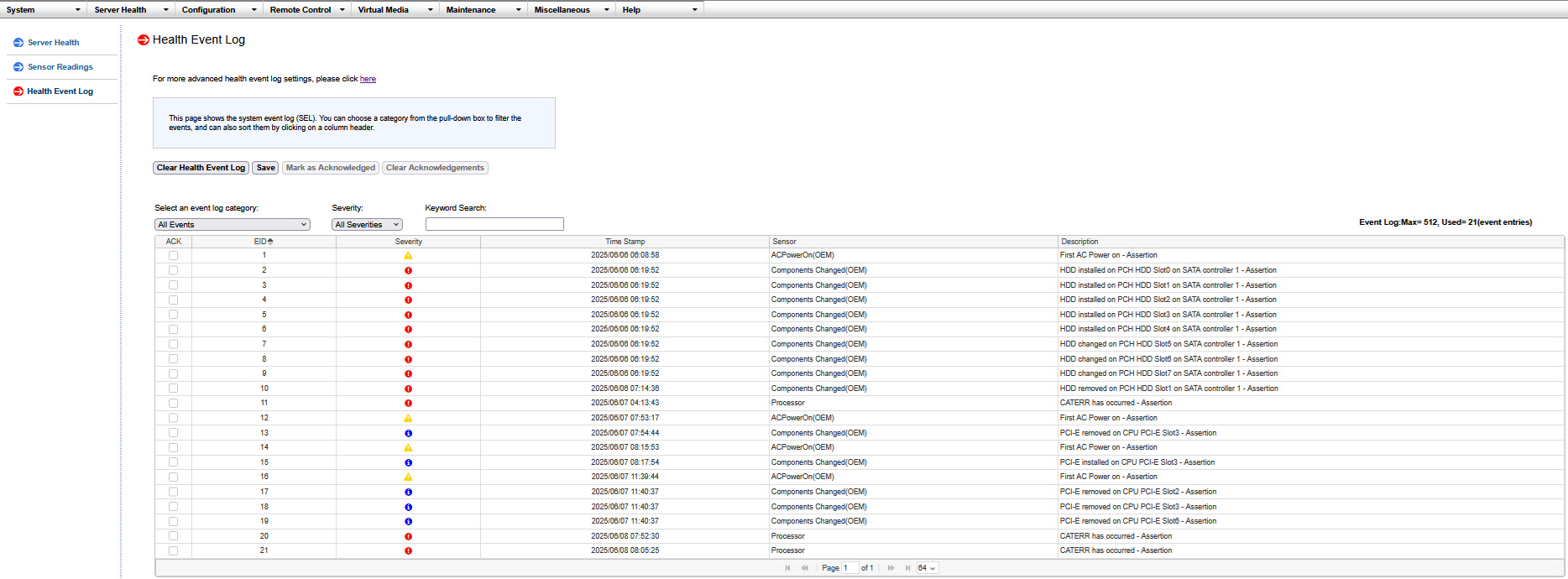
one thing i have forgotten to try is checking the state of IPMI after the system shuts down. so far looking at the IPMI logs there have been zero recorded incidents other than the “HDD installed on PCH HDD SlotXYZ on SATA controller 1 - Assertion” when i was moving drives around.
there were no logs of power rails (12 volt, 5 volt, 3.3 volt etc) having any instability…
Have you visually inspected the port on the backplane? 45HomeLab takes a lot of care in their manufacturing but they are still human. It’s possible a small metal shaving or something else fell into that SATA slot and causing the short. You can blow it out with some compressed air. Might also be worthwhile to check all the screws to make sure the backplane is indeed secured. Double check any cable connections too.
Otherwise, info@45homelab.com is your friend if you feel it’s truly a hardware/backplane problem.
I think you can use tools like ipmitool to map sensor numbers to their corresponding names. For example, i think ipmitool sdr list will show you the sensor name and its associated sensor number. It could be temperature, voltage, or something else.
problem is it is not a specific sensor, it is the processor itself
based on what i found online
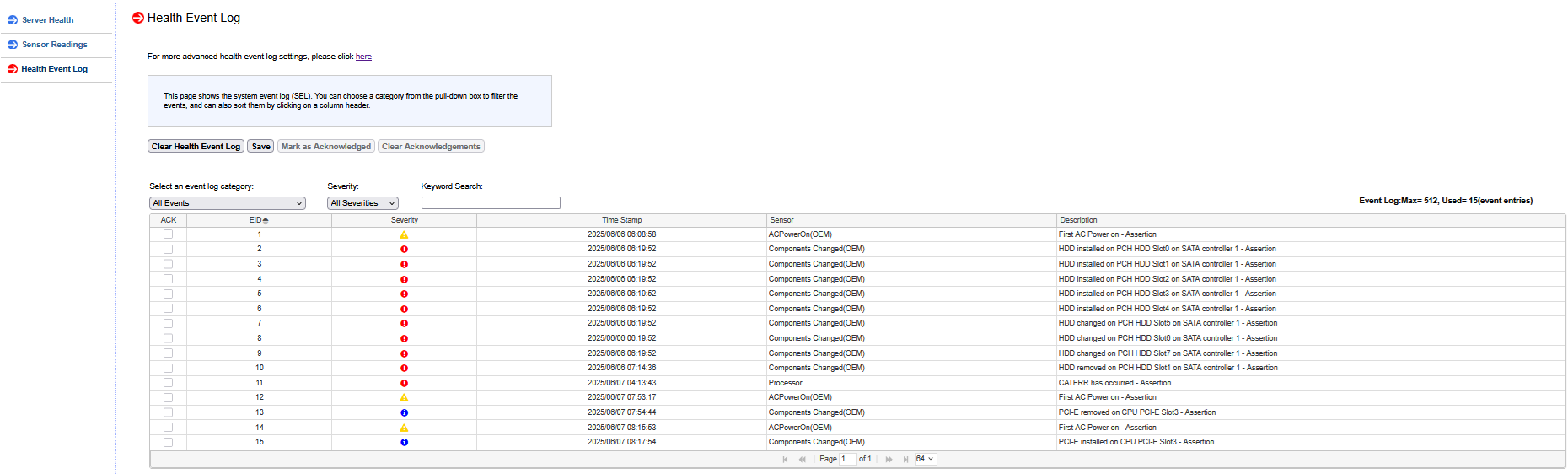
CATERR stands for Catastrophic Error, it is part of thermal protection signales. The CATERR# indicates that the system has experienced a catastrophic error and cannot continue to operate. The processor will set this signal for non-recoverable machine check errors or other unrecoverable internal errors. CATERR# is used for signaling the following types of errors:
Legacy MCERRs (Machine check errors) , CATERR# is asserted for 16 base blocks (BCLKs).
Legacy IERRs (internal errors) , CATERR# remains asserted until warm or cold reset.
So there might be something wrong with the CPU, socket, or sensor itself. Perhaps unrelated to your slot 2 issue. I’m not sure which OS you are running from your post, but TrueNAS should have some historical CPU temperature reporting. I had a CPU that would do something similar, run for a while then shut itself down although the thermal paste and heat sink were fine. I just replaced the CPU, but that was a cheap used system. Without getting a new CPU, I’m not sure how to test if that would fix your issue(s). As i think you said it’s a new system, info@45homelab.com should also be able to help identify if there’s a CPU issue.
system locked up but did not reboot on its own, but while it was locked up i was still able to access IPMI. the sensor readings looked good, but the system status in the upper right showed critical but the logs showed nothing useful. In fact i tried rebooting and commanding a power off to the system through the IPMI and it was NOT able to do so. i think the entire processor was locked up or something.
some other details i did not share previously, after i got the unit i did upgrade the BIOS and the BMC firmware to the latest released on SuperMicro for the X11SPH-nCTPF motherboard. i did that day one.
i have NOW removed all extra PCIe cards i installed.
I had a StarTech.com 4 Port PCIe Network Card - RJ45 Port - Intel i350 Chipset Amazon.com
welp, even with zero added PCIe add-on cards, the system still crashed twice within only a few minutes of each other (one at 07:52:30 AM and again at 08:05:25 AM) this morning reporting a “CATERR has occurred - Assertion”
luckilly this time crash dump logs are available to download from the IPMI interface which i have sent to 45homelab tech support. Hopefully that will shed more light on the issue.
As a next test i am going to be running the system without any added devices as i have removed all of my added HDDs. I will wait and see if the system crashes again.
Hi @wallacebrf, if you are still having issues with drives not detecting correctly, please reach out to info@45homelab.com, and we can get a support ticket entered for you.