1 Gbps is still really good, but moving even 1-2Tb per day could get your speed throttled or account flagged here in the US.
If you haven’t built this yet, how have you come to the conclusions that
single-threaded pipeline hits the boost rate? I get that the stock bronze 3204 @1.9 GHz isn’t meant for heavy computation, but how have you determined that a specific cpu will meet your needs?
parallelizable steps … I can’t remember (or find) if you need to load the entire dataset into memory. My wife’s lab uses multi terabyte sized files as well and they are not loaded entirely into memory. There are motherboards with 12 DIMMS and more, but you might not be able to fit them in HL15.
Basically, how are you determining where you want your bottleneck? (there is almost always some point in your system that is holding back a different part of your system, otherwise you are buying resources that aren’t being used)
Keep us updated, I am interested in seeing where you go with this project!
I feel a lot of the problems regarding high memory usage could be solved with something like Intel Optane memory. Though, they did just announce EOL of that whole product offering, which I have to assume was in line with their selling of the Intel SSD line to Micron.
1-2TB/day though is a LOT of data. I typically hit just above 2TB/mo and even that is if I’m consuming a lot usually through distro downloads, games, etc.
I have copies of Linux repos and MSFT updates downloaded to my home lab. As our home is mostly Internet ready (we do not use Cable TV anymore), I am consuming anywhere from 2.1 TB to 3.76 TB. The holiday will probably slow down my internet consumption.
I tracked the CPU and memory usage on a couple workloads (via the Proxmox GUI), and it was obvious that only one thread was doing any work, while all the RAM was being abused…
Had to step back a bit, however, and address the original problem of “reliable/resilient storage”, to answer the question of: “what’s the next better thing than a bunch of disparate external drives”
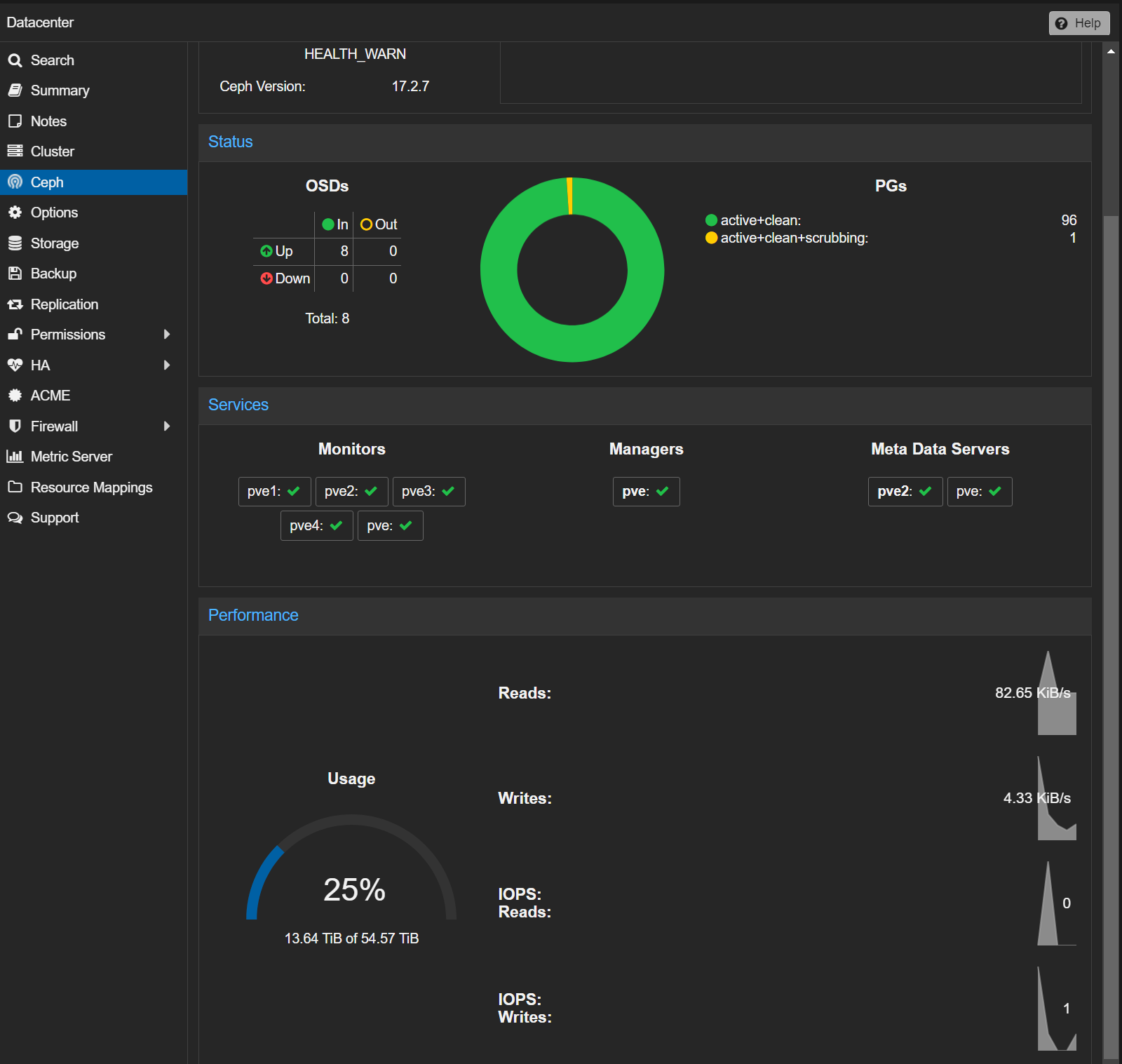
The solution I came up with is to build a minimal HA Ceph cluster.
Since 3+ HL15s are out of my budget, for now, I’ll be going for a “minipc” solution, specifically: https://www.zimaboard.com/blade/ in a 2+2 Erasure Coded setup at host-level failure domain.
The rationale being:
storage will need to grow fast over the next couple years, from 40TiB today to 0.4PiB (I think this would be the max I could cram in without needing to purchase additional nodes)
resilience: we should be able to lose 2 nodes with no data loss; using drives of different sizes and ages
Upgrade path:
add a second HDD to each node, and observe general usage patterns
if I hear complaints about read/write speeds: upgrade network to a 10GiB PCIe Gen 2 x4 board
add 3rd, and 4th drives per node
At some point (probably within a year?), the Ryzen machine currently being used for processing (AM5, 6core/12threads, 128GiB DDR5 Non-ECC RAM) will become the painful bottleneck; idea is to listen to complaints like: “why does it take weeks to process my pipeline?”
add an HL15 with a custom board (an EPYC?) as the 5th node to the zimablade HA Proxmox/Ceph Cluster
phase out zimablades as new HL15s enter the rack
I obviously don’t know what I’m doing, so this will be mostly a learning experience, aiming to build a reproducible “production ready” compute platform/cluster. So far so good: the test cephfs cluster I got running today is being used by 2 researchers, so can’t complain.
Have you experimented with dedup and compression on these datasets? Might be able to take advantage of these nifty features and spend a lot less than you thought on overall storage. Just a thought!